Étiquette : Java
LES NOUVEAUTÉS PRODUITS DU MOIS DE MARS 2024 !
Mar 28, 2024
Bonne année 2024 !
Jan 10, 2024
Les festivités de Noël
Déc 24, 2023
Tout
Dernier

DEVOXX France 2018 : le débrief
Avr 22, 2018

DEVOXX France 2017 : le débrief
Juin 1, 2017
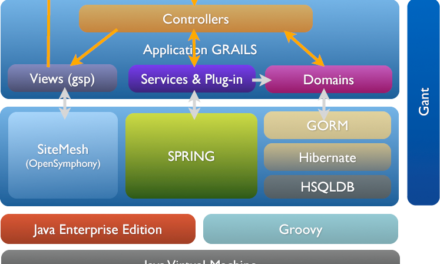
Introduction au framework Grails
Août 8, 2014

Datasources en hosted mode avec GWT 1.6
Sep 27, 2009
Produits & Astuces
Dernier

LES NOUVEAUTÉS PRODUITS DU MOIS DE MARS 2024 !
Mar 28, 2024







LES NOUVEAUTÉS PRODUITS DU MOIS D’AOÛT 2023 ...
Août 13, 2023

LES NOUVEAUTÉS PRODUITS DU MOIS DE JUILLET 2023 !
Août 1, 2023

LES NOUVEAUTÉS PRODUITS DU MOIS DE JUIN 2023 !
Juin 19, 2023

LES NOUVEAUTÉS PRODUITS DU MOIS DE MAI 2023 !
Mai 26, 2023

LES NOUVEAUTÉS PRODUITS DU MOIS D’AVRIL 2023...
Avr 11, 2023

LES NOUVEAUTÉS PRODUITS DU MOIS DE MARS 2023 !
Mar 11, 2023




Les étapes clés pour réussir l’implémentatio...
Déc 29, 2022



LES NOUVEAUTÉS PRODUITS DU MOIS DE NOVEMBRE !
Nov 28, 2022

LES NOUVEAUTÉS PRODUITS DU MOIS D’OCTOBRE !
Nov 15, 2022

LES NOUVEAUTÉS PRODUITS DU MOIS DE SEPTEMBRE !
Oct 3, 2022




Webinar : les clés du succès.
Sep 23, 2021


Offrez un parcours sans contact à vos clients
Avr 28, 2021

Les nouveautés produits du mois d’août !
Sep 2, 2019

Les nouveautés produits du mois de juillet !
Août 2, 2019
Tendances
Dernier

Retour sur l’IFTM TOP RESA 2023 !
Oct 9, 2023

IFTM TOP RESA 2023 : NOUS Y SERONS !
Août 31, 2023

Retour sur le salon IFTM TOP RESA 2022 !
Sep 26, 2022

IFTM Top Resa 2022 : le grand rendez-vou...
Sep 8, 2022

La cybersécurité chez ViaXoft
Oct 29, 2021
Webinar : les clés du succès.
Sep 23, 2021
Offrez un parcours sans contact à vos cl...
Avr 28, 2021

Comment Viaxoft tisse sa toile dans le T...
Fév 14, 2020

Selectour référence ViaXoft comme nouvea...
Nov 7, 2019

Retour sur l’IFTM Top Resa 2018
Oct 22, 2018

Nous serons à l’IFTM Top Resa 2018...
Juil 31, 2018

Flashback sur l’IFTM Top Resa 2017
Oct 4, 2017
Tech
Dernier

Zoom sur l’équipe technique
Mar 30, 2023
La cybersécurité chez ViaXoft
Oct 29, 2021
Zoom sur le métier de développeur
Mai 18, 2021

Les 8 règles du Fight Bug
Nov 8, 2018
RivieraDev 2018 : le débrief
Juin 1, 2018
DEVOXX France 2018 : le débrief
Avr 22, 2018

Le site internet de ViaXoft fait peau ne...
Déc 4, 2017

Vidéo : Pitch du Hackathon Sabre, le Rem...
Oct 25, 2017
Agile France 2017 : l’expérience V...
Sep 6, 2017

Recrutement ViaXoft : bienvenue Nicolas ...
Juil 24, 2017

Recrutement ViaXoft : une nouvelle embau...
Juin 26, 2017

TravelBox, l’outil de gestion comp...
Juin 23, 2017

Tourisme’Innov 2017
Juin 19, 2017
DEVOXX France 2017 : le débrief
Juin 1, 2017

Recrutement ViaXoft : 3 personnes intègr...
Mai 29, 2017

Future of Business Travel
Mai 18, 2017
Introduction au framework Grails
Août 8, 2014

Agile Games : soirées Agile After Work
Juin 21, 2012
Agile After Work du 13 juin 2012 –...
Juin 21, 2012

Marshmallow Challenge ou l’importa...
Avr 3, 2012
Datasources en hosted mode avec GWT 1.6
Sep 27, 2009
Inside ViaXoft
Dernier
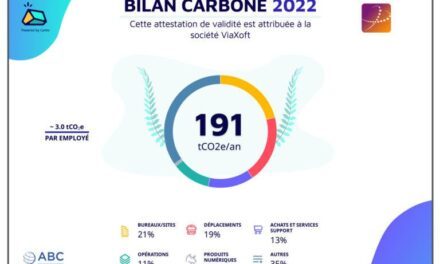
ZOOM SUR NOTRE BILAN CARBONE
Avr 10, 2024

Bonne année 2024 !
Jan 10, 2024

Les festivités de Noël
Déc 24, 2023
Zoom sur l’équipe technique
Mar 30, 2023

15 ans chez ViaXoft ? Ça se fête !
Fév 15, 2023

LES ÉQUIPES S’AGRANDISSENT !
Jan 31, 2023

Journée des Recruteurs du Travel à lR...
Jan 27, 2023

Bonne année 2023 !
Jan 6, 2023

C’est Noël chez ViaXoft !
Déc 29, 2022

LES EVENEMENTS DE NOVEMBRE !
Nov 28, 2022

SOIREE OENOLOGIE !
Nov 18, 2022

Happy Halloween !
Oct 31, 2022
Les équipes s’agrandissent !
Oct 24, 2022
Les équipes s’agrandissent !
Oct 20, 2022

LE SPORT CHEZ VIAXOFT !
Oct 20, 2022

Séminaire ViaXoft
Avr 21, 2022

Bonne année 2022 !
Jan 7, 2022

SAVE THE DATE : 20 Janvier Webinar CH
Déc 13, 2021

Zoom sur l’équipe Comptabilité
Nov 22, 2021

Zoom sur l’équipe des chargés de c...
Août 26, 2021

Zoom sur le métier d’office manage...
Août 18, 2021
Zoom sur le métier de développeur
Mai 18, 2021
Webinar du 1er Juin : Découvrez notre lo...
Mai 5, 2021

Zoom sur l’équipe commerciale
Avr 19, 2021

L’Onboarding chez ViaXoft
Avr 15, 2021

Zoom sur le rôle du Product Owner
Mar 19, 2021
Zoom sur notre équipe Transport
Fév 9, 2021

Zoom sur le service marketing & com...
Jan 27, 2021

Zoom sur l’équipe support client (...
Fév 25, 2020

Zoom sur la cellule test de ViaXoft
Nov 28, 2019

Recrutement : Hello Patrice !
Oct 25, 2019

Recrutement : Salut Elodie !
Oct 25, 2019

Recrutement : Salut Audrey !
Oct 18, 2019

ViaXoft renforce son équipe commerciale
Sep 24, 2019

Recrutement : bienvenue Mathieu !
Juin 26, 2019

Recrutement : bienvenue Delphine !
Avr 24, 2019

Recrutement : bienvenue Yann !
Avr 9, 2019

Recrutement : bienvenue Romane !
Avr 2, 2019

Recrutement : bienvenue Pauline !
Mar 26, 2019

Recrutement : bienvenue Ninon !
Mar 25, 2019
Les 8 règles du Fight Bug
Nov 8, 2018
Retour sur l’IFTM Top Resa 2018
Oct 22, 2018
Nous serons à l’IFTM Top Resa 2018...
Juil 31, 2018

Recrutement : Laure, Chargée de clientèl...
Mar 27, 2018

Recrutement : Johanne, International Bus...
Fév 23, 2018

Recrutement : Sébastien rejoint le servi...
Jan 26, 2018

Recrutement : Macarena et Gregory rejoig...
Déc 4, 2017
Vidéo : Pitch du Hackathon Sabre, le Rem...
Oct 25, 2017

Recrutement : Anaïs rejoint l’équi...
Oct 25, 2017
Revues de presse
Dernier

Viaxoft a bien grandi
Mar 27, 2023
Viaxoft chez Tourmag : “Les voyant...
Mar 9, 2023

ViaXoft se lance sur le marché belge
Fév 14, 2020
Comment Viaxoft tisse sa toile dans le T...
Fév 14, 2020
Selectour référence ViaXoft comme nouvea...
Nov 7, 2019

Quotidien du Tourisme : ViaXoft souffle ...
Sep 11, 2018